DeepSeek's surprisingly inexpensive AI model challenges industry giants. The Chinese startup claims to have trained its powerful DeepSeek V3 neural network for a mere $6 million, utilizing only 2048 GPUs, a stark contrast to competitors' significantly higher costs. This seemingly low figure, however, only reflects pre-training GPU usage and excludes substantial research, refinement, data processing, and infrastructure expenses.
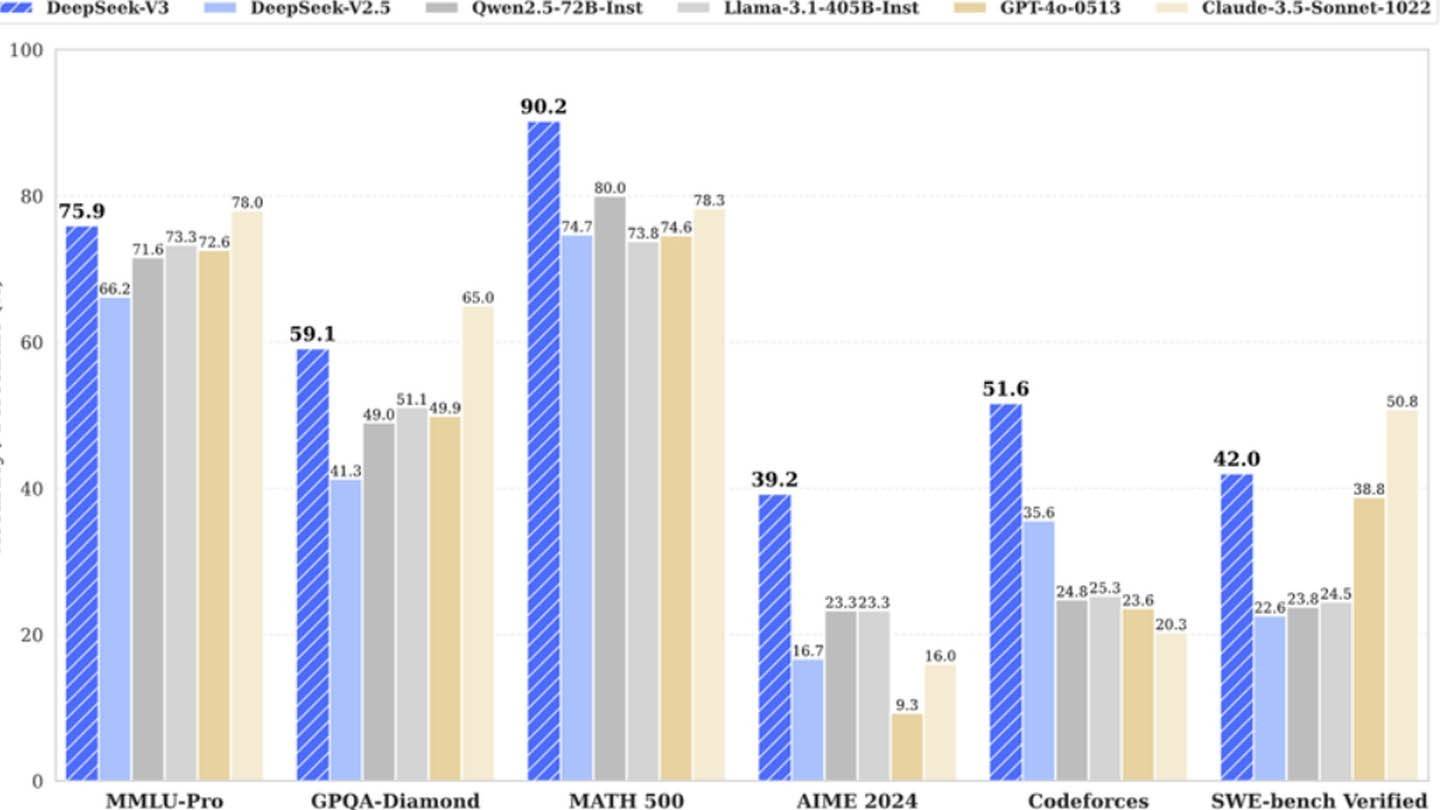 Image: ensigame.com
Image: ensigame.com
DeepSeek V3's innovative architecture contributes to its efficiency. Key technologies include Multi-token Prediction (MTP), which forecasts multiple words simultaneously; Mixture of Experts (MoE), employing 256 neural networks for accelerated training; and Multi-head Latent Attention (MLA), focusing on crucial sentence elements for improved accuracy.
 Image: ensigame.com
Image: ensigame.com
However, a closer look reveals a substantial investment. SemiAnalysis uncovered DeepSeek's use of approximately 50,000 Nvidia Hopper GPUs, valued at roughly $1.6 billion, with operational costs reaching $944 million. This contradicts the initial $6 million claim.
 Image: ensigame.com
Image: ensigame.com
DeepSeek's success stems from a combination of factors: substantial funding (over $500 million invested in AI development), technological advancements, and a highly skilled team earning substantial salaries (some exceeding $1.3 million annually). The company's independent structure and ownership of its data centers contribute to its agility and efficiency.
 Image: ensigame.com
Image: ensigame.com
While DeepSeek's "budget-friendly" narrative is arguably inflated, its achievement remains significant. The company demonstrates that a well-funded, independent AI entity can effectively compete with established players, despite the substantial investment ultimately required. The contrast is stark when comparing training costs: DeepSeek's R1 cost $5 million, while ChatGPT4 cost a reported $100 million. Despite the higher actual cost, DeepSeek's model remains comparatively cheaper than its competitors.
 LATEST ARTICLES
LATEST ARTICLES 









